
Representing Hierarchical Data with Poincaré Embeddings!
#representationlearning #embeddings #neuralnetworks #poincaré

When I started exploring Representation Learning early in my career, I was amazed at how critical this concept was for Applied Data Science and Machine Learning. And, it’s easy to understand why. Back then, all the buzz was around the use of Word2Vec, GloVe, FastText, etc, for generating embeddings for text, and it’s surprising that these models are still relevant today!
The principle is simple - Embed words/sentences into an N-dimensional vector space where the distance between the vectors of 2 words encodes their semantic similarity. In practice, if done correctly, you would find that the embedding of the word “car” and “bike” would be clustered closer to each other than the embedding of “car” and “spaceship”. Given good vector representations or embeddings of your data, you could explore a large variety of downstream models or use them as features for secondary tasks! But this same concept is expandable to other types of data - images, tabular, graphs, etc.
Flashback - At the time, I was working with a database of “Skillsets” which were structured as a hierarchy, for example, Programming → Python → Pandas → Dataframe. And, during my quest to “master” the world of Representation learning, I came across this very unique challenge of representing Hierarchical Data. I wanted to know how I could create embeddings for these “skills” using the hierarchical relationships between them and use these as part of my downstream estimators.
Enter Poincaré Embeddings!
This post will focus on implementing these rather than exploring the maths behind them but here is a quick overview. So feel free to skip this section!!
“However, while complex symbolic datasets often exhibit a latent hierarchical structure, state-of-the-art methods typically learn embeddings in Euclidean vector spaces, which do not account for this property. For this purpose, we introduce a new approach for learning hierarchical representations of symbolic data by embedding them into hyperbolic space – or more precisely into an n-dimensional Poincaré ball.”
— Nickel, M., & Kiela, D. (2017). Poincaré embeddings for learning hierarchical representations. Advances in neural information processing systems, 30.
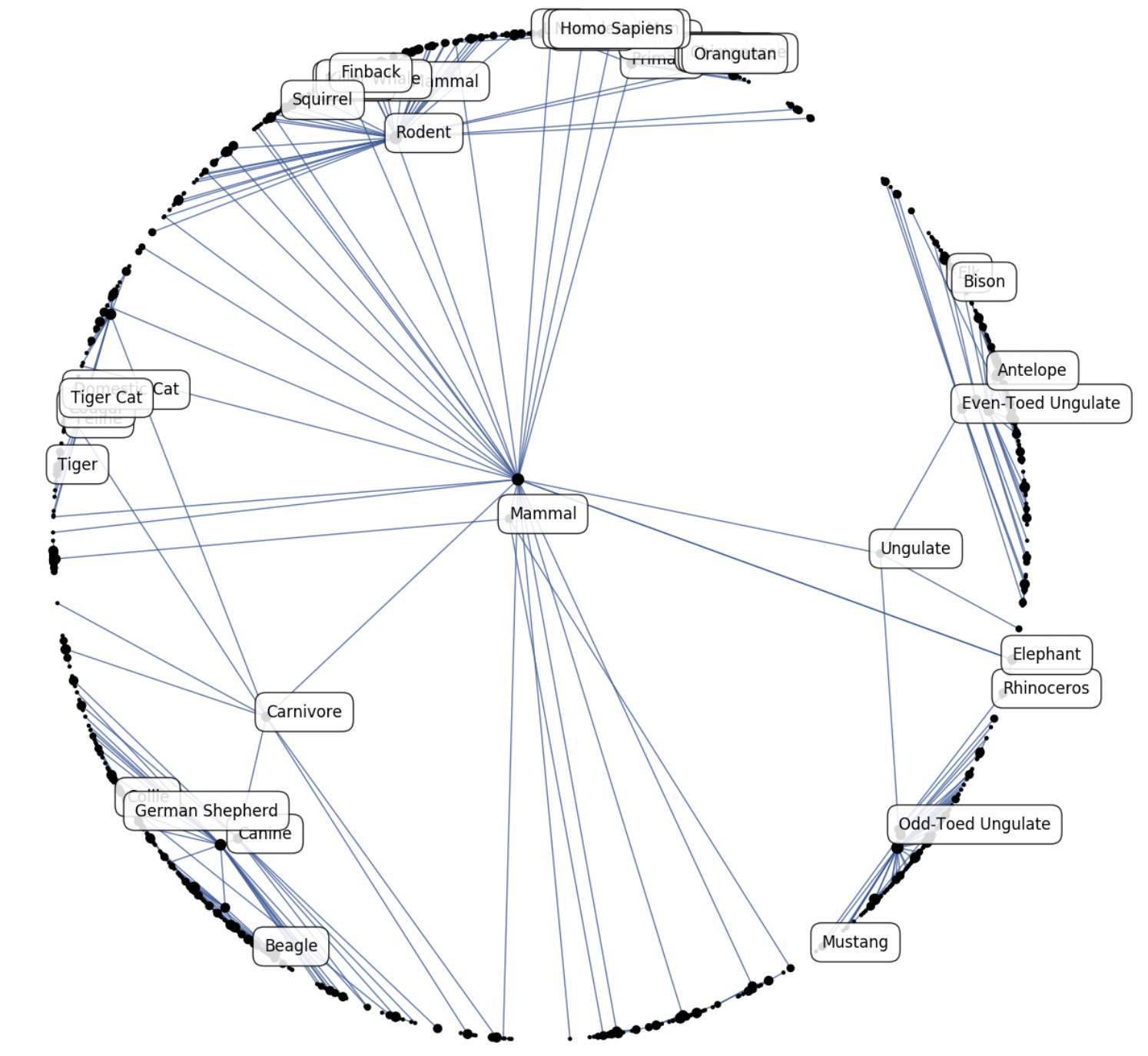
Poincaré embeddings allow you to create hierarchical embeddings in a non-euclidean space. The vectors on the outside of the Poincaré ball are lower in the hierarchy compared to the ones in the center.

The transformation to map a Euclidean metric tensor to a Riemannian metric tensor is an open d-dimensional unit ball.

Distances between 2 vectors in this non-euclidean space are calculated as -
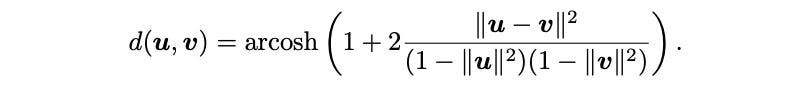
Once plotted, your hierarchical data might look like this when mapped over a Poincaré ball.
The research paper for Poincaré embeddings is wonderfully written and you will find some easy implementations in popular libraries for them as well. Needless to say, they are underrated.
Two popular implementations that you can use are found in -
gensim.models.poincaretensorflow_addons.PoincareNormalize
Implementing Poincaré Embeddings!
Let’s start by generating some hierarchical data. If you have access to such a dataset already, feel free to use that. But for our exploration of the concept, I find that the synset relationships in NLTK’s Wordnet are perfect!
Here is a function I wrote to generate this data (inspired by this repo) -
def generate_data(root='mathematics.n.01'):
"""
Script to generate sample DAG data using input root
"""
#INSTALL THE CORPUS WORDNET (UNCOMMENT FIRST RUN)
#import nltk
#nltk.download('wordnet')
#nltk.download('omw-1.4')
#IMPORT DEPENDENCIES
import random
from nltk.corpus import wordnet as wn
#SET ROOT/TARGET AS MAMMAL(NOUN)
target = wn.synset(root)
print('target', target.name())
#FIND ALL NOUNS IN WORDNET
words = wn.words()
nouns = set([])
for word in words:
nouns.update(wn.synsets(word, pos='n'))
print(len(nouns), 'nouns')
#FETCH ALL HYPERNYMS WITH PATH TO TARGET
hypernyms = []
for noun in nouns:
paths = noun.hypernym_paths()
for path in paths:
try:
pos = path.index(target)
for i in range(pos, len(path)-1):
hypernyms.append((noun, path[i]))
except Exception:
continue
hypernyms = list(set(hypernyms))
print(len(hypernyms), 'hypernyms')
#SHUFFLE AND SAVE ALL RELATIONSHIP TUPLES
random.shuffle(hypernyms)
data = [(n1.name(), n2.name()) for n1, n2 in hypernyms]
print(len(data), 'relations')
return data
#generating data with root as "bird"
data = generate_data('bird.n.01')
# target bird.n.01
# 82115 nouns
# 3435 hypernyms
# 3435 relations#Show 20 sample datapoints
print(data[:20])
[('australian_turtledove.n.01', 'columbiform_bird.n.01'),
('snowy_egret.n.01', 'bird.n.01'),
('american_gallinule.n.01', 'gallinule.n.01'),
('banded_stilt.n.01', 'stilt.n.03'),
('plover.n.01', 'shorebird.n.01'),
('great_bowerbird.n.01', 'passerine.n.01'),
('jaeger.n.01', 'coastal_diving_bird.n.01'),
('blue_jay.n.01', 'new_world_jay.n.01'),
('new_world_jay.n.01', 'passerine.n.01'),
('auklet.n.01', 'aquatic_bird.n.01'),
('hedge_sparrow.n.01', 'passerine.n.01'),
('shoveler.n.02', 'anseriform_bird.n.01'),
('peahen.n.01', 'gallinaceous_bird.n.01'),
('pheasant_coucal.n.01', 'coucal.n.01'),
('goldfinch.n.02', 'oscine.n.01'),
('old_squaw.n.01', 'sea_duck.n.01'),
('cochin.n.01', 'domestic_fowl.n.01'),
('corncrake.n.01', 'aquatic_bird.n.01'),
('least_sandpiper.n.01', 'shorebird.n.01'),
('warbler.n.02', 'oscine.n.01')]This hierarchical data is structured as a list of 3,435 “child → parent” tuples. Let’s quickly plot this to see what these might look like.
Also, try using other roots such as
mathematics.n.01ormammal.n.01
import networkx as nx
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(18,14))
g = nx.Graph(data)
nx.draw(g, with_labels=True)
Not very readable but the local and global structure is somewhat visible.
Let’s use Gensim to implement Poincare Embeddings. Want to know how easy it is? Just 2 lines of code as marked below -
import numpy as np
from gensim.models.poincare import PoincareModel
#MODEL TRAINING
model = PoincareModel(data, size=50, negative=10) #<---
model.train(epochs=30) #<---
#FETCH VECTORS AND STORE
vectors = {}
keys = model.kv.index_to_key
for k in keys:
vectors[k] = model.kv.get_vector(k)
#STACKING EMBEDDINGS TO A NDARRAY
embeddings = np.stack(vectors.values())
print(len(keys),'keys')
print(embeddings.shape[0], 'embeddings')
print(embeddings.shape[1], 'dimensions')872 keys
872 embeddings
50 dimensionsGreat, so we have 872 nodes in our hierarchy and each one is represented with a 50-dimensional vector in this non-euclidean space. Let’s use the Poincare distance implementation from Gensim to see if the hierarchical relationships are encoded in the model.
print('owl vs hawk:', model.kv.similarity('owl.n.01','hawk.n.01'))
print('eagle vs bald_eagle:', model.kv.similarity('eagle.n.01','bald_eagle.n.01'))
print('golden_eagle vs bald_eagle:', model.kv.similarity('golden_eagle.n.01','bald_eagle.n.01'))
print('owl vs barn_owl:', model.kv.similarity('owl.n.01','barn_owl.n.01'))
print('barn_owl vs spotted_owl:', model.kv.similarity('barn_owl.n.01','spotted_owl.n.01'))
print('barn_owl vs mandarin_duck:', model.kv.similarity('barn_owl.n.01','mandarin_duck.n.01'))owl vs hawk: 0.31635084567961813
eagle vs bald_eagle: 0.8757754918787964
golden_eagle vs bald_eagle: 0.8758848440323967
owl vs barn_owl: 0.6982827095728305
barn_owl vs spotted_owl: 0.738832541978296
barn_owl vs mandarin_duck: 0.1329321668369148Excellent! Related nodes are closer to each other in this space as expected! Let’s maybe use Principle Component Analysis to plot this space in 3D just to get a sense of how this is clustered.
NOTE: We are using PCA to project a non-euclidean space into a 3 dimensional euclidean space, so take it with a grain of salt!
import pandas as pd
import plotly.express as px
from sklearn.decomposition import PCA
pca = PCA(3)
components = pca.fit_transform(embeddings)
keys = model.kv.index_to_key
cols = ['component1','component2','component3']
plot_df = pd.DataFrame(components, columns=cols, index=keys)
# PLOTTING ONLY 100 SAMPLE VECTORS
plot_df = plot_df.head(100) #<---
px.scatter_3d(plot_df,
x='component1', y='component2', z='component3',
text=plot_df.index, opacity=0.5, height=900, width=900)


And as expected, we see the outline of the sphere where these embeddings exist. Also, we see that the outer edge of the sphere has a higher density of nodes due to the nature of how these embeddings are mapped onto this curved space. The clusters of related nodes are quite visible in the additional zoomed-in views.
Want to use these in your neural networks?
Worry not! You can use, tensorflow_addons.layers.PoincareNormalize and add this layer over your Embedding layer!
from tensorflow.keras import layers, Model, utils
import tensorflow_addons as tfa
X = np.random.random((100,10))
y = np.random.random((100,))
inp = layers.Input((10,))
x = layers.Embedding(500, 5)(inp)
x = tfa.layers.PoincareNormalize(axis=-1)(x) #<-------
x = layers.Flatten()(x)
out = layers.Dense(1)(x)
model = Model(inp, out)
model.compile(optimizer='adam', loss='binary_crossentropy')
utils.plot_model(model, show_shapes=True, show_layer_names=False)
model.fit(X, y, epochs=3)So there you have it! Poincaré Embeddings in all their glory. It’s a powerful concept that I hope you can now use as part of your model experiments when you have to work with hierarchical data!